Redis与Mysql数据库一致性与预防缓存雪崩
引言
最近秋招也是在如火如荼的进行,好多公司的面试都涉及了高并发场景下的缓存数据库Redis与后端数据库(Mysql/Pgsql等)的一致性校验,与缓存雪崩的预防方式.
正好我的百度网盘提取码查询服务就使用了后端Mysql前端Redis缓存的数据库架构,今天就来探讨一下对于高并发场景Redis与Mysql的一致性处理与缓存雪崩的预防方式.
Redis是什么?
Redis作为一款高效的内存数据存储系统,凭借其优异的读写性能和丰富的数据结构支持,被广泛应用于缓存层以提升整个系统的响应速度和吞吐量.尤其是在与关系型数据库(如MySQL、PostgreSQL等)结合使用时,通过将热点数据存储在Redis中,可以在很大程度上缓解数据库的压力,提高整体系统的性能表现.
双写一致性的重要性?
我们在访问大量数据读写业务的时候会受限于硬盘IO拖慢访问速度,所以像是权限验证、用户管理等业务一般都会使用Redis作为中间件缓存用户的数据.
如果前后端数据出现不同步,就会发生严重的数据不同步与用户体验滞后,所以双写的一致性就尤为重要.
| 问题类型 | 典型表现 | 影响场景 |
|---|---|---|
| 事务边界失控 | 非数据库操作(如 Redis 更新)无法纳入事务 | 缓存与数据库数据不一致 |
| 性能瓶颈 | 同步双写导致接口响应时间线性增长 | 高并发场景吞吐量骤降 |
| 级联故障 | 任一存储节点故障导致整体操作失败 | 系统可用性下降 |
| 数据丢失 | 异步补偿机制设计不当,消息丢失或重试失败 | 业务逻辑错误 |
如何实现双写一致性
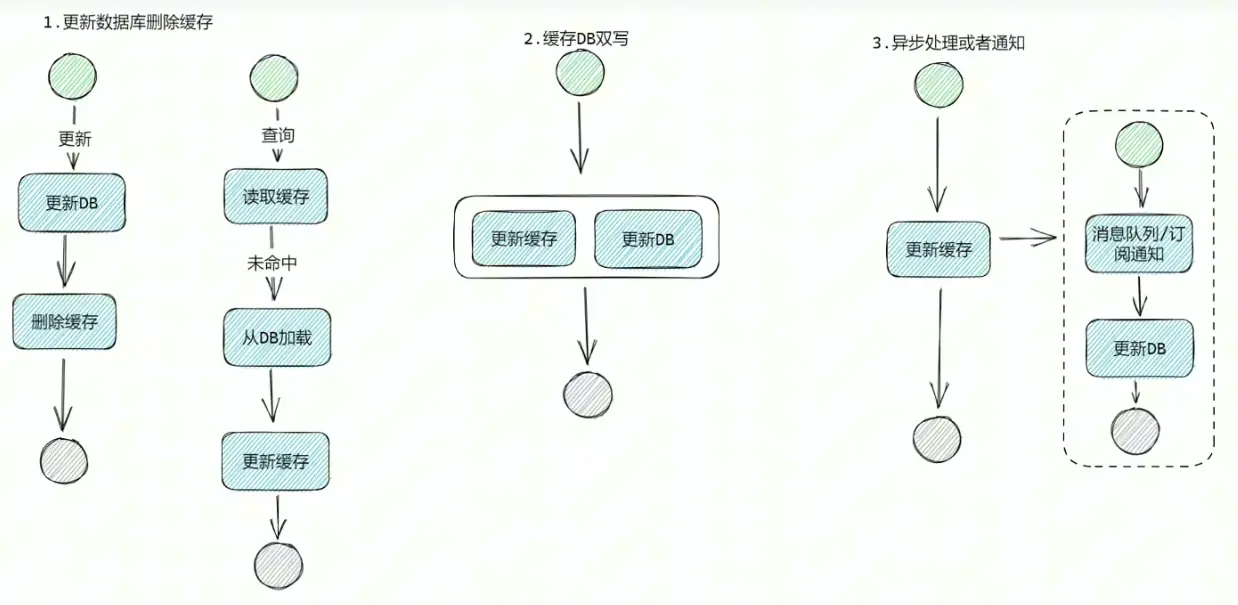
以我的项目为例,我采用的是先删除Mysql数据,再将Redis数据删除.对于目前我服务的低并发来说,这种架构很大程度避免了同时多人读取同一个过时数据,Mysql的数据不会被再次缓存导致双写不一致.
因为我的业务没有需要修改的数据且并发量较低所以主要的验证是通过中间层主动验证有效性保证传回数据有效.
对于还需要修改数据的业务会用到一个叫做延时双删的方式保证全链路数据一致性
延时双删: 即删除Redis缓存写入Mysql数据后隔一段时间再删除Redis缓存完成数据更新
为什么有两次删除?
第一次删除是删除过时的旧数据,确保后续读请求会去数据库查询新数据并刷新缓存.
第二次删除是在延迟一段时间后再次清除缓存,防止在数据库更新完成前,有并发请求读取到旧数据并写入缓存,从而保证缓存最终与数据库保持一致.
通俗来讲
第一次删缓存,是为了告诉系统: “旧缓存已经失效了,请用最新的数据来更新”
更新数据库后,可能会有一定延迟
在这段时间里,如果有并发请求过来读数据,可能就会读到”旧数据”,并重新写回缓存
所以我们再做第二次删除,把可能存在过时的”脏缓存”清理掉,确保后续请求读到的是更新后的一致数据
当面对更大访问量的服务时,任何一瞬间都可能涌入数万甚至数十万的请求,这时延迟双删机制在高并发场景下便显得力不从心,可能存在缓存删除不及时、重复写入干扰、甚至短暂脏读的问题。
因此,在这类高性能、高一致性要求的系统中,我们更倾向于采用基于binlog异步删除缓存的方案,通过监听数据库的变更日志(binlog),将数据更新事件异步通知到缓存层,实现更加高效、稳定、解耦的缓存一致性控制.
最典型的使用场景是监听数据库的 binlog 日志,捕获其中的 INSERT、UPDATE、DELETE 等操作,将其解析为结构化数据,封装为消息后发布到消息队列中.随后由独立的缓存同步服务消费这些消息,识别出受影响的缓存 Key,并异步删除(或更新)对应 Redis 中的缓存数据.
对于更大规模的全球化服务使用的多DC(Multi-DataCenter)数据库往往涉及到更复杂的异步读写策略、一致性模型选择以及跨地域数据复制机制,由于其设计复杂度较高,这里就不展开讨论.
缓存雪崩
并不是所有数据都会一直被高频访问,这时候就需要释放缓存防止占用过多内存,所以一般缓存都有一个有效期.
但是,我们现在假设一个场景:
淘宝618大促,大量商品正在被上万人访问抢购
为了减少数据库压力,所有商品的基本信息会被缓存在 Redis 中,缓存设置了一个有效期十小时.
但是到了第二天因为晚上访问量到达低谷所以大量缓存在有效期结束后被释放
中午开启了一个抢卷活动导致服务器突然涌入了大量访问,因为并发量过大缓存没有及时的同步,这时候大量的请求直接穿透缓存发送到数据库
数据库瞬间收到数百倍于平常的请求,响应延迟激增,而期间的服务线程阻塞、超时重试进一步加剧数据库压力
这个案例是不是很像你们在京东前段时间秒送抢卷下单遇到的情况,每到一个整点领卷时间,服务器都会被大量访问涌入,而优惠卷的数量,优惠信息和用户拥有的优惠卷信息都在被高频刷新访问,而缓存可能正好在这时候大量失效了.
想要解决这种问题也很简单
- 使用随机的有效期,避免集中失效
- 使用主动更新机制,对于单位时间内请求量高的缓存进行延期
在大型系统中,为了避免缓存击穿和缓存雪崩带来的数据库雪崩效应,通常还会采用布隆过滤器前置校验与热点缓存探测机制相结合的策略,以过滤无效请求、降低非必要数据库访问压力,从而提升系统的稳定性和缓存命中率.
参考文献
- 标题: Redis与Mysql数据库一致性与预防缓存雪崩
- 作者: MoGuQAQ
- 创建于 : 2025-08-12 21:41:51
- 更新于 : 2025-08-12 21:41:51
- 链接: https://blog.moguq.top/posts/25081202/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
